
してみました。用途は不明
 Arakaki Tokyo
Arakaki Tokyo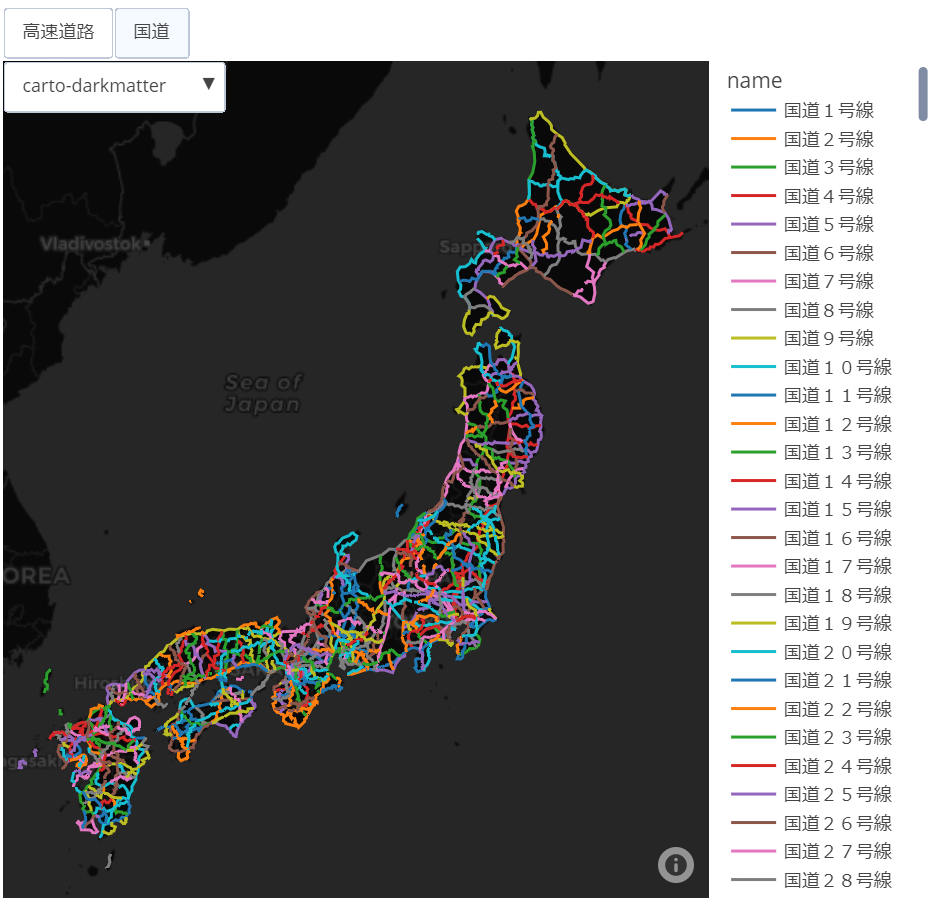 Arakaki Tokyo
Arakaki Tokyo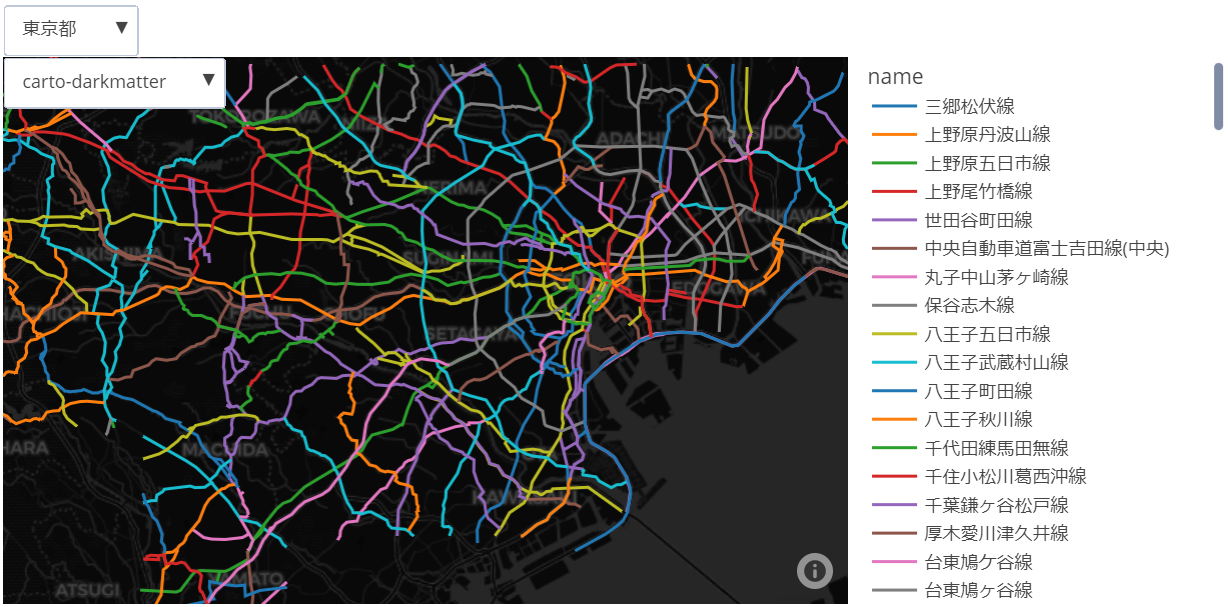
ぱっと見では程よく描画されているように思えますが、元のデータが1995年のものとのことで、現在供用されている道路の一部区間が繋がっていなかったりします。
また、ざっと全都道府県を確認したところ、なぜか沖縄県の南部の地域だけラインがごちゃごちゃしています。これも元のデータを忠実に描画した結果です。
元データのページに記載がある通り、
※本データには出典不明・年度不明のデータが含まれており、データの一部は領域外にあるものがあるため、利用には注意を要する。
という感じです。
技術的なこと
以下では技術的なことをつらつらと書いていきます。
記載されているコードは全てGoogle Colaboratoryで実行可能です。
元データの構造がツラい
例として東京都の道路データを取得し、name列だけ少し整形したDataFrameがこちらです。
geometryを細かく見てみると、全てLineStringsオブジェクトで多くが2~4個のポイントで構成されていることが分かります。
これが最初のツラいところで、諸々の処理をする際には路線毎に1行で表現してほしいわけですよ。
これはgeopandasのdissolveメソッドで解決できるのですが、結局細切れのLineStringを力技で一つのMultiLineStringにしただけなので、どうにもスッキリしない違和感が残ります。
具体的な弊害としては、いざデータをgeojsonに出力するときにファイルサイズが無駄に大きくなってしまいます。
plotlyで描画するのがツラい
ここまではデータをデータとして見てきましたが、地理データであるからには視覚的に情報を確認したいところです。
ざっと全体を見るだけなら、GeoDataFrameのplotメソッドでもいいでしょう。
しかしながらより詳細に確認したい場合にはやはり物足りません。
そこでplotlyを使いたいわけですが、なんとplotlyでLineStringを描画する場合にはgeojsonやGeoDataFrameをそのまま読み込むことができません。😡
ではどうするかというと、行毎にポイントを表すDataFrameを作る必要があるのです。
公式のサンプルから該当の処理を持ってくると以下のようになります。
一つのLineStringを展開する毎にNoneを追加しているのはLineString同士が繋がってしまうのを防ぐためです。
既に確認したように、元データは細切れのLineStringで一つの路線を表していますが、その順番や向きはなにも保障されていません。
plotlyでは指定されたlat, lonのポイントを順番に繋いで描画するため、区切りとしてのNoneが必要なのです。
路線毎に色分けしたい
描画のためにわざわざDFを変換しないといけない時点でツラいのですが、その描画されたものもマウスホバーしないとどの路線なのか分かりません。
路線ごとに色分けする方法として、先のdf_for_plotly関数に手を加えて実現できないこともないのですが、JSの処理がめちゃくちゃ遅くなるので割愛します。
根本的な解決策は後述しますが、ここでは簡単にbufferメソッドでLineStringをPolygon化する方法を紹介します。
ポリゴン化してしまえばplotlyのchoropleth_mapboxでデータをそのまま読み込んでもらえるという発想なのですが、そもそもchoropleth_mapboxの用途に適さないので20レコードぐらいでも重くなってしまいます。
実用には供さないけどこういうこともできる、ぐらいのTipsでした。
解決策 -- LineString をまとめる --
さて、じゃあ結局どうすりゃいいのという話ですが、そもそも一本の道路が細切れのLineStringになっているのが諸悪の根源な訳なので、元データを一路線につき一つのLineString(枝分かれ等の場合にのみMultiLineString)に変換すれば良いわけです。
さらにそこからplotlyで描画用にシーケンシャルなポイントのDFを生成できれば良いわけです。
という訳でできあがった関数がこちらです。
特定路線のLineString(またはMultiLineString)のポイントを全て展開し、同じポイントを探して繋げていきます。
最終的に順序付けられたポイントのリストからGeoDataFrame or DataFrameオブジェクトを作成して返します。
import pandas as pd
import geopandas as gpd
from enum import Enum
from shapely.geometry import LineString, MultiLineString
def reduce_lines(gdf, to, name):
'''
parameters
gdf: geopandas.GeoDataFrame
geometry列がLineString型またはMultiLineString型
to: str
"pandas" or "geopandas"
name: 戻り値のDataFrameのname列に使われる
return
pandas.DataFrame columns: ['name', 'group', 'lon', 'lat' ] or
geopandas.GeoDataFrame columns: ['name', 'geometry']
'''
class Direction(Enum):
FORWARD = 0
BACKWARD = 1
def list_to_gdf(l):
'''
parameters
l: list of tuple of lon/lat
return
geopandas.GeoDataFrame
columns: ['geometry' ]
'''
gdf = gpd.GeoDataFrame({"geometry": [LineString(l)]})
return gdf
def list_to_df(l):
'''
parameters
l: list of tuple of lon/lat
return
pandas.DataFrame
columns: ['group', 'lon', 'lat' ]
'''
df = pd.DataFrame(l, columns=['lon', 'lat'])
df['group'] = f'{name}_{group_count}'
return df
def line_to_tuple(iterable, list_of_tuple):
for i in iterable:
if isinstance(i, LineString):
list_of_tuple.append(tuple(i.coords))
elif isinstance(i, MultiLineString):
line_to_tuple(i, list_of_tuple)
if to == "pandas":
list_to = list_to_df
elif to == "geopandas":
list_to = list_to_gdf
else:
raise TypeError("'to' argument must be 'pandas' or 'geopandas'")
return
work = list()
dfs = list()
lines = list()
line_to_tuple(gdf.geometry, lines)
lines = list(set(lines))
dir = Direction.BACKWARD
group_count = 1
while lines:
if not work:
work.extend(lines.pop(0))
continue
if dir == Direction.BACKWARD:
for i, line in enumerate(lines):
if work[-1] in line:
l = list(lines.pop(i))
if l[0] != work[-1]:
l.reverse()
work.extend(l[1:])
break
else:
dir = Direction.FORWARD
continue
else:
for i, line in enumerate(lines):
if work[0] in line:
l = list(lines.pop(i))
if l[-1] != work[0]:
l.reverse()
work[0:0] = l[:-1]
break
else:
dfs.append(list_to(work))
group_count += 1
work = list()
dir = Direction.BACKWARD
if work:
dfs.append(list_to(work))
all = pd.concat(dfs)
if to == "geopandas":
all = all.dissolve()
else:
all.reset_index(drop=True, inplace=True)
all["name"] = name
return all
def convert_all(gdf, to):
all = list()
for name in gdf.name.unique():
all.append(reduce_lines(gdf.query(f'name.str.startswith("{name}")', engine='python'), to, name))
all_df = pd.concat(all)
all_df.reset_index(drop=True, inplace=True)
return all_df
元データからLineStringをまとめたGeoDataFrameに変換してみます。
余談
全国の国道を見ると59~100号が抜けてるんですよね。その理由は
昭和39年の道路法改正後から一般国道の追加指定には3桁の番号が付けられているためです。
道路:道の相談室:道に関する各種データ集 - 国土交通省
らしいです。
また、東京のマップで環八が羽田空港手前で途切れているのは重用区間だからかと思われますが、他の路線では重なって描画されているところもあるので冒頭で言及した不備の一つでしょう。
それはいいとして、重用区間での標識表示は「~連おにぎり」と呼ばれるようです。
道路、奥が深い😌
【マニアックですが・・・】
— 国土交通省 福井河川国道事務所 (@mlit_fukui) June 17, 2020
日本で唯一の「4連おにぎり」標識
国道が4つ重複する箇所に設置
27号がメインのため、8号より上にあり、「下克上」と呼ばれるそうです。
福井県内にありますので、良かったら探してみてください。#おにぎり #道路標識 #国道 #4連 pic.twitter.com/L1KfqVRl9Z


