$$
% 変数名
\global\def\A{\boldsymbol{A}}
\global\def\D{\boldsymbol{D}}
\global\def\E{\boldsymbol{E}}
\global\def\L{\boldsymbol{L}}
\global\def\U{\boldsymbol{U}}
\global\def\b{\boldsymbol{b}}
\global\def\x{\boldsymbol{x}}
\global\def\y{\boldsymbol{y}}
\global\def\P{\boldsymbol{P}}
% 数式
\global\def\EQ{\A\x = \b}
% 行列・ベクトルの展開表記
\global\def\expA{
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n}\\
a_{21} & a_{22} & \cdots & a_{2n}\\
\vdots & \vdots & & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
}
\global\def\expL{
\begin{bmatrix}
l_{11} & 0 & \dots & 0 \\
l_{21} & l_{22} & \ddots & \vdots \\
\vdots & \vdots & \ddots & 0 \\
l_{n1} & l_{n2} & \dots & l_{nn}
\end{bmatrix}
}
\global\def\expLunit{
\begin{bmatrix}
1 & 0 & \dots & 0 \\
l_{21} & \ddots & \ddots & \vdots \\
\vdots & \ddots & \ddots & 0 \\
l_{n1} & \dots & l_{n n-1} & 1
\end{bmatrix}
}
\global\def\exL{
\begin{bmatrix}
l_{11} & & \\
\vdots & \ddots & \\
l_{n1} & \dots & l_{nn}
\end{bmatrix}
}
\global\def\expU{
\begin{bmatrix}
u_{11} & u_{12} & \dots & u_{1n} \\
0 & u_{22} & \dots & u_{2n} \\
\vdots & \ddots & \ddots & \vdots \\
0 & \dots & 0 & u_{nn}
\end{bmatrix}
}
\global\def\expUunit{
\begin{bmatrix}
1 & u_{12} & \dots & u_{1n} \\
0 & \ddots & \dots & \vdots \\
\vdots & \ddots & \ddots & u_{n-1 n} \\
0 & \dots & 0 & 1
\end{bmatrix}
}
\global\def\exU{
\begin{bmatrix}
u_{11} & \dots & u_{1n} \\
& \ddots & \vdots \\
& & u_{nn} \\
\end{bmatrix}
}
\global\def\expD{
\begin{bmatrix}
d_{11} & 0 & \dots & 0 \\
0 & d_{22} & \dots & \vdots \\
\vdots & \ddots & \ddots & 0 \\
0 & \dots & 0 & d_{nn}
\end{bmatrix}
}
\global\def\expx{\begin{bmatrix}x_1 \\ x_2 \\ \vdots\\ x_n\end{bmatrix}}
\global\def\exx{\begin{bmatrix}x_1 \\ \vdots\\ x_n\end{bmatrix}}
\global\def\expy{\begin{bmatrix}y_1 \\ y_2 \\ \vdots\\ y_n\end{bmatrix}}
\global\def\exy{\begin{bmatrix}y_1 \\ \vdots\\ y_n\end{bmatrix}}
\global\def\expb{\begin{bmatrix}b_1 \\ b_2 \\ \vdots\\ b_n\end{bmatrix}}
\global\def\exb{\begin{bmatrix}b_1 \\ \vdots\\ b_n\end{bmatrix}}
\global\def\rtrb#1{{#1}\left\downarrow\vphantom{#1}\right.}
\global\def\rbrt#1{{#1}\left\uparrow\vphantom{#1}\right.}
$$
今回から数値計算によって連立一次方程式を解く方法を見ていきます。
以降を通じて扱う連立一次方程式(linear system of equations)を$\EQ$と書くことにします。ここで、
$\A = \expA\;,\;\; \b = \expb\;,\;\; \x = \expx\;.$
であり、$\A$と$\b$がそれぞれ既知であるとき、$\x$を求める問題です。
これら連立一次方程式を構成するパーツを
- $\A$: 係数行列(coefficient matrix)
- $\b$: 定数項、定数ベクトル(constant vector)
- $\x$: 解、解ベクトル(solution)
と呼ぶことにします。
連立一次方程式の解法は大別して直接法(direct method)と反復法(iteration method)があります。
本記事では直接法としてガウスの消去法、ガウス・ジョルダン法、LU分解を取り上げます。
ガウスの消去法
$$
% 行列 ⇔ 数式 の部品定義
\global\def\Ga{
\begin{bmatrix}
a_{11} & a_{12} & a_{13}\\
a_{21} & a_{22} & a_{23}\\
a_{31} & a_{32} & a_{33}
\end{bmatrix}
}
\global\def\Gx{\begin{bmatrix}x_1 \\ x_2 \\ x_3\end{bmatrix}}
\global\def\Gb{\begin{bmatrix}b_1 \\ b_2 \\ b_3\end{bmatrix}}
\global\def\eqi {a_{11} x_{1} + a_{12} x_{2} + a_{13} x_{3} = b_1}
\global\def\eqii {a_{21} x_{1} + a_{22} x_{2} + a_{23} x_{3} = b_2}
\global\def\eqiii{a_{31} x_{1} + a_{32} x_{2} + a_{33} x_{3} = b_3}
$$
$$
\Ga\Gx = \Gb \Leftrightarrow \begin{cases}\begin{aligned}\eqi\\ \eqii\\ \eqiii\end{aligned}\end{cases}
$$
この方程式を、解$\x$が変化しないように、最終的には
$$
% 行列 ⇔ 数式 の部品定義
\global\def\Ga{
\begin{bmatrix}
a_{11} & a_{12} & a_{13}\\
& a^{(1)}_{22} & a^{(1)}_{23}\\
& & a^{(2)}_{33}
\end{bmatrix}
}
\global\def\Gx{\begin{bmatrix}x_1 \\ x_2 \\ x_3\end{bmatrix}}
\global\def\Gb{\begin{bmatrix}b_1 \\ b^{(1)}_2 \\ b^{(2)}_3\end{bmatrix}}
\global\def\eqi {a_{11} x_{1} + a_{12} x_{2} + a_{13} x_{3} = b_1\,\,}
\global\def\eqii { a^{(1)}_{22} x_{2} + a^{(1)}_{23} x_{3} = b^{(1)}_2}
\global\def\eqiii{ a^{(2)}_{33} x_{3} = b^{(2)}_3}
$$
$$
\Ga\Gx = \Gb \Leftrightarrow \begin{cases}\begin{aligned}\eqi\\ \eqii\\ \eqiii\end{aligned}\end{cases}
$$
という形に変形し、$x_3, x_2, x_1$の順に解$\x$を求める方法です。
import numpy as np
import sympy as sp
import scipy.linalg as lin
import random
下の3×3行列で$\x$を求める過程を考えてみます。
rng = np.random.default_rng()
def getAxb(n, by, low=-5, high=5, pivot=False):
'解がただ1つに決まるようなA, x, bを返す'
if by == sp:
while True:
A = sp.Matrix(n, n, rng.integers(low, high, size=n**2))
if A.det(): break
if pivot: A = A.permute(A.LUdecomposition()[2])
x = sp.Matrix(n, 1, rng.integers(low, high, size=n))
b = A*x
elif by == np:
while True:
A = rng.integers(low, high, size=n**2).reshape((n, n))
if np.linalg.det(A): break
if pivot:
A = lin.lu(A)[0].T.astype(int)@A
x = rng.integers(low, high, size=n).reshape((n, 1))
b = A@x
return A, x, b
n = 3
A, x, b = getAxb(n, by=sp, pivot=True)
eq = sp.Eq(sp.MatMul(A, x), b)
eq
まず$\A$と$\b$を水平方向に結合した行列$(\A|\b)$を作ります。
以下、この行列を操作していきます。
m = sp.Matrix.hstack(A, b)
m
前進消去(forward elimination)
行列$\A$を上三角化させます。この過程をガウスの消去法の前進消去(forward elimination)と呼びます。
1行目を定数倍して2,3行目に加える。(1)
E1 = sp.eye(n)
E1[1, 0] = -m[1, 0]/m[0, 0]
E1[2, 0] = -m[2, 0]/m[0, 0]
m1 = E1*m
sp.Eq(sp.MatMul(E1, m), m1)
同様に2行目を定数倍して3行目に加える。(2)
E2 = sp.eye(n)
E2[2, 1] = -m1[2, 1]/m1[1, 1]
m2 = E2*m1
sp.Eq(sp.MatMul(E2, m1), m2)
後退代入(backward substitution)
下から$x_n$の値を求めながら、求まった値を上に代入していきます。
この過程を後退代入(backward substitution)と呼びます。
行列の操作としては、上三角化された$\A$を単位行列化することに相当します。
$x_3$を求める。
E3 = sp.eye(n)
E3[2, 2] = 1/m2[2, 2]
m3 = E3*m2
sp.Eq(sp.MatMul(E3, m2), m3)
3行目を定数倍して1,2行目に加える。
E4 = sp.eye(n)
E4[0, 2] = -m3[0, 2]
E4[1, 2] = -m3[1, 2]
m4 = E4*m3
sp.Eq(sp.MatMul(E4, m3), m4)
$x_2$を求める。
E5 = sp.eye(n)
E5[1, 1] = 1/m4[1, 1]
m5 = E5*m4
sp.Eq(sp.MatMul(E5, m4), m5)
2行目を定数倍して1行目に加える。
E6 = sp.eye(n)
E6[0, 1] = -m5[0, 1]
m6 = E6*m5
sp.Eq(sp.MatMul(E6, m5), m6)
$x_1$を求める。
E7 = sp.eye(n)
E7[0, 0] = 1/m6[0, 0]
m7 = E7*m6
sp.Eq(sp.MatMul(E7, m6), m7)
最終的に4列目が解$\x$となっています。
# 確認
sp.Eq(x, m7[:, 3], evaluate=False)
計算量
上では説明のため、基本行列を左から掛ける行基本変形によって計算を行いました。
しかし実際に計算を行う際は、結果が明らかであったり変わらない部分はサボることができます。
例えば前進消去における(1)の計算では、予め$\frac{a_{21}}{a_{11}}$と$\frac{a_{31}}{a_{11}}$の値を計算しておき、それぞれ1行目の2列目以降に掛けた値を2,3行目の2列目以降から引きます。
1列目が0になることは明らかなので、乗除算と加減算を1回ずつサボることができます。
また、後退代入の際も計算が必要なのは定数項のみとなります。
このような考え方でガウスの消去法のアルゴリズムをnumpyで実装したのが下の関数です。
def Gauss1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
以下の計算で動作確認
def n2s(m: np.ndarray) -> sp.matrices.dense.MutableDenseMatrix:
'2次元のndarrayをsympyのMatrixに変換する'
return sp.Matrix(*m.shape, m.flatten())
n = 3
A, x, b = getAxb(n, by=np, pivot=True)
_A, _x, _b = map(n2s, [A, x, b])
# 見やすくするためsympyに変換
sp.Eq(sp.MatMul(_A, _x), _b)
ans = Gauss1(A, b)
print("x = ans:", np.allclose(x, ans))
ans
コードに沿って計算量を考えてみます。
なおndarray(や多くのプログラミング言語での配列)のインデックスは0始まり、range([start, ]end)は0(またはstart)からend-1までの整数列を返すことにご留意ください。
前進消去
乗除算
- 6~10行のfor文で$n-1$回の繰り返し:$\sum^{n-2}_{c=0}$
- 7~10行のfor文で$n-(c+1)$回の繰り返し:$\sum^{n-1}_{r=c+1}$
以上より
$$
\begin{aligned}
& コードに沿って列を0から数える\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;& & (参考)列を1から数える \\
& \sum^{n-2}_{c=0}\sum^{n-1}_{r=c+1}n-c+1 & = & \sum^{n-1}_{c=1}\sum^{n-1}_{r=c}n-c+2\\
= & \sum^{n-2}_{c=0}(n-c-1)(n-c+1) & = & \sum^{n-1}_{c=1}(n-c)(n-c+2) \\
\end{aligned}
$$
n, c, r = sp.symbols('n c r')
forward_joujo = sp.Sum(sp.Sum(n-c+1, (r, c+1, n-1)), (c, 0, n-2)).doit()
forward_joujo.simplify()
加減算
以上より
$$
\begin{aligned}
& コードに沿って列を0から数える\;\;\;\;\;\;\;\;\;\;\;\; & & (参考)列を1から数える \\
& \sum^{n-2}_{c=0}(n-c-1)(n-c) & = & \sum^{n-1}_{c=1}(n-c)(n-c+1) \\
\end{aligned}
$$
forward_kagen = sp.Sum(sp.Sum(n-c, (r, c+1, n-1)), (c, 0, n-2)).doit()
forward_kagen.simplify()
後退代入
乗除算
$\global\def\tmp{\sum^{0}_{r=n-1} = \sum^{n-1}_{r=0}}$
- 12~14行のfor文でn回の繰り返し:$\tmp$
以上より
$$
\sum^{n-1}_{r=0}r+1
$$
back_joujo = sp.Sum(r+1, (r, 0, n-1)).doit()
back_joujo#.simplify()
加減算
以上より
$$
\sum^{n-1}_{r=0}r
$$
back_kagen = sp.Sum(r, (r, 0, n-1)).doit()
back_kagen#.simplify()
まとめると以下のようになります。
print("乗除算:")
(forward_joujo + back_joujo).simplify()
print("加減算:")
(forward_kagen + back_kagen).simplify()
【参考】前進消去で対角成分を1にする
ガウスの消去法のアルゴリズムとして、前進消去の過程で対角成分を1にしていく説明も見かけます。
結論から言えばどちらも計算量に違いはありません。(乗除算は前進消去、後退代入で異なるが合計は一致)
以下のGauss1_1関数で確認します。
def Gauss1_1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n):
m[c, c+1:] /= m[c, c]
for r in range(c+1, n):
m[r, c+1:] -= m[r, c] * m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
Gauss1とGauss1_1の差分
# 縮小表示
import difflib as diff
t1 = '''
def Gauss1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def Gauss1_1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n):
m[c, c+1:] /= m[c, c]
for r in range(c+1, n):
m[r, c+1:] -= m[r, c] * m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
# 動作確認
A, x, b = getAxb(3, by=np, pivot=True)
print("x = ans:", np.allclose(x, Gauss1_1(A, b)))
前進消去
- 6~9行のfor文で$n$回の繰り返し:$\sum^{n-1}_{c=0}$
- 7行目で除算$n-c$回
- 8~9行のfor文で$n-(c+1)$回の繰り返し:$\sum^{n-1}_{r=c+1}$
以上より
$$
\begin{aligned}
& \sum^{n-1}_{c=0}\big(n-c+\sum^{n-1}_{r=c+1}\big(n-c\big)\big) \\
= & \sum^{n-1}_{c=0}(n-c-1)(n-c) \\
\end{aligned}
$$
n, c, r = sp.symbols('n c r')
forward_joujo = sp.Sum(n-c+sp.Sum(n-c, (r, c+1, n-1)), (c, 0, n-1)).doit()
forward_joujo.simplify()
後退代入
- 13~16行のfor文でn回の繰り返し:$\tmp$
- 13行目で乗算r回
以上より
$$
\sum^{n-1}_{r=0}r
$$
back_joujo = sp.Sum(r, (r, 0, n-1)).doit()
back_joujo#.simplify()
まとめると以下のようになります。
print("乗除算:")
(forward_joujo + back_joujo).simplify()
枢軸(ピボット)選択(pivoting)
さて、上で実装したアルゴリズムは以下の場合に失敗します。
対角成分が0
最初から$\A$の(1, 1)成分が0なら分かりやすいですが、前進消去中に対角成分が0になることもありえます。(以下例)
n = 3
while True:
A1 = np.array(rng.integers(1, 10, size=n**2)).reshape((n, n))
A1[1, 0:2] = 2*A1[0, 0:2]
if np.linalg.det(A1) != 0: break
x1 = np.array(rng.integers(10, size=n)).reshape((n, 1))
b1 = A1@x1
symA, symb, symx = map(n2s, [A1, b1, x1])
eq1 = sp.Eq(sp.MatMul(symA, symx), symb)
eq1
# RuntimeWarning: divide by zero
Gauss1(A1, b1)
対角成分の絶対値が非常に小さい
絶対値が非常に小さい値による除算で絶対値が非常に大きい値が生まれます。
その値と他の値を加減算することで情報落ちや丸め誤差が生じます。
n = 3
while True:
A2 = np.array(rng.integers(1, 10, size=n**2), dtype=np.float64).reshape((n, n))
A2[0, 0] = 1e-14
if np.linalg.det(A2) != 0: break
x2 = np.array(rng.integers(10, size=n)).reshape((n, 1))
b2 = A2@x2
symA, symb, symx = map(n2s, [A2, b2, x2])
eq2 = sp.Eq(sp.MatMul(symA, symx), symb)
eq2
rx = Gauss1(A2, b2)
print(f'計算結果:\n{rx}, \n\n相対誤差:\n {np.abs(rx - x2)/x2}')
部分枢軸選択(partial pivoting)
これらを避けるため、前進消去の際に最も絶対値の大きい値を対角成分にするように行列を入れ替えることを枢軸(ピボット)選択(pivoting)といいます。
また、ガウスの消去法における対角成分のように、計算を行う上で最初に着目する要素をpivot(pivot element)といいます。
なお、入れ替えを行のみで行う場合を部分枢軸選択(partial pivoting)といいます。
以下のGauss2関数で部分枢軸選択を追加(8~9行)して、上で失敗した例を試してみます。
def Gauss2(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
Gauss1とGauss2の差分
# 縮小表示
t1 = '''
def Gauss1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def Gauss2(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
対角成分が0になる例
eq1
Gauss2(A1, b1)
対角成分の絶対値が小さい例
eq2
Gauss2(A2, b2)
ガウス・ジョルダン法(Gauss–Jordan elimination)
ガウスの消去法は前進消去・後退代入に2ステップで計算しましたが、前進消去の過程で上三角行列ではなく直接対角行列(単位行列)にしていく方法をガウス・ジョルダン法(Gauss–Jordan elimination)といいます。
以下の例で流れを確認します。
A, x, b = getAxb(3, by=sp, pivot=True)
sp.Eq(sp.MatMul(A, x), b)
m = sp.Matrix.hstack(A, b)
m
1列目の掃き出し
E1 = sp.eye(n)
E1[1, 0] = -m[1, 0]/m[0, 0]
E1[2, 0] = -m[2, 0]/m[0, 0]
m1 = E1*m
sp.Eq(sp.MatMul(E1, m), m1)
2列目の掃き出し
E2 = sp.eye(n)
E2[0, 1] = -m1[0, 1]/m1[1, 1]
E2[2, 1] = -m1[2, 1]/m1[1, 1]
m2 = E2*m1
sp.Eq(sp.MatMul(E2, m1), m2)
3列目の掃き出し
E3 = sp.eye(n)
E3[0, 2] = -m2[0, 2]/m2[2, 2]
E3[1, 2] = -m2[1, 2]/m2[2, 2]
m3 = E3*m2
sp.Eq(sp.MatMul(E3, m2), m3)
$\x$の各値を求める
E4 = sp.diag(1/np.array(list(m3.diagonal())), unpack=True)
m4 = E4*m3
sp.Eq(sp.MatMul(E4, m3), m4)
計算量
ガウスの消去法では対角成分を1にするタイミングで計算量に違いはありませんでしたが、ガウス・ジョルダン法の場合は掃き出し操作の前に対角成分を1にしておく方が若干計算量は少なくなります。
とはいえ、いずれの場合でも$n^3$の係数で比較するとガウスの消去法より1.5倍多く計算することになります。
以下ではピボット選択は行わないものとして、乗除算の回数のみ数えることにします。
最後に対角成分を1にする
上の例をそのまま関数化したのが下のGauss_Jordan1です。
計算量は$\frac{n(n^2+2n-1)}{2}$となります。
def Gauss_Jordan1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(n):
if r == c: continue
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
for r in range(n):
m[r, n] /= m[r, r]
return m[:, n:]
Gauss2とGauss_Jordan1の差分
# 縮小表示
t1 = '''
def Gauss2(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def Gauss_Jordan1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(n):
if r == c: continue
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
for r in range(n):
m[r, n] /= m[r, r]
return m[:, n:]
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
# 動作確認
A, x, b = getAxb(3, by=np)
np.allclose(x, Gauss_Jordan1(A, b))
- for文でn回繰り返し:$\sum^{n-1}_{c=0}$
- 乗除算n回
以上より、$\sum^{n-1}_{c=0}\big((n-1)(1+n-c)\big) + n$
n, c, r = sp.symbols('n c r')
(sp.Sum((n-1)*(1+n-c), (c, 0, n-1))+n).doit().simplify()
掃き出し操作の前に対角成分を1にする
この場合の計算量は$\frac{n^2(n+1)}{2}$になります。
def Gauss_Jordan1_1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
m[c, c+1:] /= m[c, c]
for r in range(n):
if r == c: continue
m[r, c+1:] -= m[r, c] * m[c, c+1:]
return m[:, n:]
Gauss_Jordan1とGauss_Jordan1_1の差分
# 縮小表示
t1 = '''
def Gauss_Jordan1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(n):
if r == c: continue
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
for r in range(n):
m[r, n] /= m[r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def Gauss_Jordan1_1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
m[c, c+1:] /= m[c, c]
for r in range(n):
if r == c: continue
m[r, c+1:] -= m[r, c] * m[c, c+1:]
return m[:, n:]
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
# 動作確認
A, x, b = getAxb(3, by=np)
np.allclose(x, Gauss_Jordan1(A, b))
以上より、$\sum^{n-1}_{c=0}\big(n-c + (n-1)(n-c)\big)$
sp.Sum(n-c+(n-1)*(n-c), (c, 0, n-1)).doit().simplify()
逆行列を求める
前回の記事では余因子展開によって逆行列を求める方法を紹介しましたが、ガウス・ジョルダン法のアルゴリズムで$\A$と$\b$ではなく$\A$と単位行列を結合して同様の操作を行うことで、逆行列を求めることができます。
下のGauss_Jordan2関数では逆行列にも対応しました。
def Gauss_Jordan2(m1, m2):
n = m1.shape[0]
m = np.hstack([m1, m2])
for c in range(n):
# 部分枢軸選択
idx = np.arange(m1.shape[0])
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c:
idx[[c, p]] = idx[[p, c]]
m[[c, p]] = m[[p, c]]
e = np.eye(n)
e[:, c] = -m[:, c]/m[c, c]
e[c, c] = 1/m[c, c]
m = e @ m
return m[:, n:] if m2.shape[1] == 1 else m[idx, n:]
Gauss_Jordan1とGauss_Jordan2の差分
# 縮小表示
t1 = '''
def Gauss_Jordan1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
for c in range(n):
# 部分枢軸選択
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c: m[[c, p]] = m[[p, c]]
for r in range(n):
if r == c: continue
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
for r in range(n):
m[r, n] /= m[r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def Gauss_Jordan2(m1, m2):
n = m1.shape[0]
m = np.hstack([m1, m2])
for c in range(n):
# 部分枢軸選択
idx = np.arange(m1.shape[0])
p = np.argmax(np.abs(m[c:, c]))+c
if m[p, c] == 0: raise ValueError(f'matrix \n{A} is not invertible.')
if p != c:
idx[[c, p]] = idx[[p, c]]
m[[c, p]] = m[[p, c]]
e = np.eye(n)
e[:, c] = -m[:, c]/m[c, c]
e[c, c] = 1/m[c, c]
m = e @ m
return m[:, n:] if m2.shape[1] == 1 else m[idx, n:]
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
# 動作確認:Ax=bのxを求める
A, x, b = getAxb(3, by=np)
np.allclose(x, Gauss_Jordan1(A, b))
# 動作確認:Aの逆行列を求める
inv = Gauss_Jordan2(A, np.eye(A.shape[0]))
np.allclose(np.linalg.inv(A), inv)
LU分解(LU decomposition)
行列$\A$を、以下のような下三角行列(Lower triangular matrix)$\L$と上三角行列(Upper triangular matrix)$\U$の積($\A = \L\U$)で表すことをLU分解といいます。
$$
\L = \expL\;,\;\; \U = \expU\;.
$$
連立方程式とどのように関係するかというと、式$\EQ$を$(\L\U)\x=\b$で表せる場合には以下のようにして$\x$を求めることができます。
まず$\U\x = \y$として、
$$
\L\y = \b \Leftrightarrow \exL\rtrb{\exy} = \exb
$$
を$y_1$から$y_n$の順に$\y$について解きます。次にこの$\y$を定数ベクトルとする連立一次方程式
$$
\U\x=\y \Leftrightarrow \exU\rbrt{\exx} = \exy
$$
を$x_n$から$x_1$の順に、$\x$について解きます。
上で$\y$について解く過程を前進代入(forward substitution)、$\x$について解く過程を後退代入(backward substitution)と呼びます。
前進代入と後退代入の計算量は合計でガウスの消去法の後退代入2回分です。また、後述する通りLU分解自体の計算量はガウスの消去法の前進消去と同等なので、連立方程式を1つ解くだけの場合にはわざわざLU分解をするうまみはありません。
しかしながら、$\A$を固定して複数の異なる$\b$で$\x$を解くような場合、毎回ガウスの消去法を使うと$O(n^3)$の計算を行うのに対し、$\A$をLU分解しておけば$O(n^2)$の計算で済みます。
sympy, scipyでの利用法
まずはLU分解を用いて連立方程式を解く流れをSymPy, SciPyを使って確認します。
また実行時間の簡単な比較によってLU分解の利点を示します。
既に何気なく登場しているsympyは数式処理(記号処理)が専門なので、scipyに比べると実行時間はとても遅いです。
sympy
LU分解
sympyのLUdecompositionメソッドでは(L, U, perm)が返されます。
ここでperm(permutation)は部分枢軸選択によって入れ替えた行のペアのリストです。なお、絶対値によるピボット選択は行われません。
n = 3
# あえてピボット選択が必要なAを作る
while True:
A, x, b = getAxb(n, by=sp)
L, U, p = A.LUdecomposition()
if len(p): break
print(f'{L=}\n\n{U=}\n\n{p=}')
したがって結果は以下のように解釈できます。ここで$\P$は行を入れ替える基本行列です。
$\P\A = \L\U$
sympyでは単位行列のpermuteメソッドにpを与えて行列$\P$を作ります。
P = sp.eye(n).permute(p)
eq = sp.Eq(sp.MatMul(P, A), sp.MatMul(L, U))
print("PA = LU:", eq.doit())
eq
$\A$でpermuteメソッドを実行しても同様です。
sp.Eq(A.permute(p), L*U)
または
$A = \P^{-1}\L\U$
eq = sp.Eq(A, sp.MatMul(P.inv(), L, U))
print("A = P^{-1}LU:", eq.doit())
eq
置換行列$\P$は直交行列で$\P^{-1} = \P^\top$なので、上記は$A = \P^\top\L\U$と同値です。
sp.Eq(A, P.T*L*U)
左から$\P^{-1}$を掛けることはsympyのpermuteBkwd(またはpermute(perm, direction='backward'))メソッドでも実現できます。
sp.Eq(A, (L*U).permuteBkwd(p))
連立方程式を解く
LU分解した後に連立方程式を解くには以下のメソッドが有用です。
少し不格好ですが、下のコードでは$\L\y = \b$を$\y$について解いた後、$\U\x = \y$を$\x$について解いています。
eq = sp.Eq(sp.MatMul(A, x), b)
eq
ans = U.upper_triangular_solve(L.lower_triangular_solve(b.permute(p)))
print(f"{x == ans=}")
ans
時間比較
参考として、以下の場合でn×n行列$\A$を固定して連立方程式を解くのに掛かる平均時間を比較してみます。
- $\A$のsolveメソッドで$\A\x = \b$を解く
- LU分解して$\L$のlower_triangular_solveメソッドで$\L\y = \b$を、$\U$のupper_triangular_solveメソッドで$\U\x = \y$を解く
nを1ずつ増やしながら試すと違いがよく分かるかと思います。(n=18あたりから1.の実行時間が耐えられなくなってくると思います。)
import time
def mytime(p=True):
'関数fの実行時間を測定する'
def deco(f):
begin = time.time()
f()
secs = time.time() - begin
m, s = divmod(secs, 60)
if p: print(f'{m:02g}:{s:06.3f}')
return secs
return deco
def mytimeit(n =7):
'関数fを繰り返し実行した時間を測定する'
def deco(f):
records = np.array([mytime(p=False)(f) for _ in range(n)])
m, s = divmod(records.mean(), 60)
print(f'{m:02g}:{s:06.3f} +- {records.std()*1000:6.3f}(ms)')
return records
return deco
n = 10
A, *_ = getAxb(n, by=sp)
1. $\A$のsolveメソッドで$\A\x = \b$を解く
@mytimeit()
def _():
x = sp.Matrix(n, 1, lambda *_: random.randint(-5, 5))
b = A*x
A.solve(b)
2. LU分解して$\L$のlower_triangular_solveメソッドで$\L\y = \b$を、$\U$のupper_triangular_solveメソッドで$\U\x = \y$を解く
L, U, p = A.LUdecomposition()
@mytimeit()
def _():
x = sp.Matrix(n, 1, lambda *_: random.randint(-5, 5))
b = A*x
U.upper_triangular_solve(L.lower_triangular_solve(b.permute(p)))
scipy
import scipy.linalg as lin
LU分解
scipyでは以下の関数でLU分解を行います。
- scipy.linalg.lu
- scipy.linalg.lu_factor
1. scipy.linalg.lu
この関数では$\A = \P \L \U$となるような2次元のndarray(p, l, u)を返します。
sympyのLUdecompositionメソッドとは異なり、絶対値でもピボット選択を行います。
n = 4
A, *_ = getAxb(n, by=np)
p, l, u = lin.lu(A)
print("A = PLU:", np.allclose(A, p@l@u))
# 見やすくするためsympyに変換
_A, _p, _l, _u = map(n2s, [A, p.astype(int), l, u])
sp.Eq(_A, sp.MatMul(_p, sp.MatMul(_l, _u)))
2. scipy.linalg.lu_factor
$$
\global\def\expLU{
\begin{bmatrix}
u_{11} & u_{12} & u_{13}& \dots & u_{1n}\\
l_{21} & u_{22} & u_{23}& \dots & u_{2n}\\
l_{31} & l_{32} & u_{33} & \dots& \vdots\\
\vdots & \vdots & \ddots & \ddots& \vdots\\
l_{n1} & l_{n2} & \dots & l_{nn-1} & u_{nn}
\end{bmatrix}}
$$
この関数は$\L$(対角成分が1)と$\U$を重ねて$\expLU$のようにしたndarray(lu)と、ピボット選択の操作を記録した1次元のndarray(piv)を返します。
n = 4
A, *_ = getAxb(n, by=np)
lu, piv = lin.lu_factor(A)
print(f'{lu=}\n\n{piv=}')
pivの扱いが初見では分かりづらいですが、これは以下のように解釈できます。
print('AのLU分解において以下の操作を順次行った。')
for frm, to in enumerate(piv):
if frm == to: continue
print(f' {frm+1}行目と{to+1}行目を入れ替える')
というわけで、sympyのpermuteを参考に行を入れ替える関数を作り、
def permute(m, p, direction:str='forward'):
'''Interchange row i of matrix with row p[i].
Parameters
----------
m : ndarray
p : list
lu_factorで返されるpivのような配列
direction : 'forward', 'backward'
'''
d = 1
if direction == 'backward': d = -1
elif direction != 'forward': raise ValueError('"direction" takes "forward" or "backward"')
idx = np.arange(m.shape[0])
for frm, to in list(enumerate(p))[::d]:
if frm == to: continue
idx[[frm, to]] = idx[[to, frm]]
return m[idx]
lu_factorの実行結果を以下のように操作すれば、$\P\A = \L\U$となるような$\P$, $\L$, $\U$を得ることができます。
l = lin.tril(lu, -1) + np.eye(n)
u = lin.triu(lu)
p = permute(np.eye(n), piv)
print("PA = LU:", np.allclose(p@A, l@u))
# 見やすくするためsympyに変換
_A, _p, _l, _u = map(n2s, [A, p.astype(int), l, u])
sp.Eq(sp.MatMul(_p, _A), sp.MatMul(_l, _u))
連立方程式を解く
以下3つの方法を紹介します。
- scipy.linalg.solve
- scipy.linalg.solve_triangular
- scipy.linalg.lu_solve
1. scipy.linalg.solve
$\EQ$を解きます
n = 3
A, x, b = getAxb(n, by=np)
# 見やすくするためsympyに変換
_A, _x, _b = map(lambda a:n2s(a.astype(int)), [A, x, b])
sp.Eq(sp.MatMul(_A, _x), _b)
ans = lin.solve(A, b)
print(f"x = ans:", np.allclose(x, ans))
ans
2. scipy.linalg.solve_triangular
lu関数などで$\L$と$\U$を取得していれば、$\L\y = \b$と$\U\x = \y$を効率よく解くことができます。
n = 3
A, x, b = getAxb(n, by=np)
# 見やすくするためsympyに変換
_A, _x, _b = map(lambda a:n2s(a.astype(int)), [A, x, b])
sp.Eq(sp.MatMul(_A, _x), _b)
p, l, u = lin.lu(A)
ans = lin.solve_triangular(u, lin.solve_triangular(l, p.T@b, lower=True))
print(f"x = ans:", np.allclose(x, ans))
ans
3. scipy.linalg.lu_solve
lu_factor関数の戻り値をそのまま引数としてとります。
n = 3
A, x, b = getAxb(n, by=np)
# 見やすくするためsympyに変換
_A, _x, _b = map(lambda a:n2s(a.astype(int)), [A, x, b])
sp.Eq(sp.MatMul(_A, _x), _b)
ans = lin.lu_solve(lin.lu_factor(A), b)
print(f"x = ans:", np.allclose(x, ans))
ans
時間比較
上記3つの方法による実行時間を比較してみます。
条件はsympyでの場合と同様ですが、文字通り桁違いのサイズの行列でも短時間で計算できることが分かります。
1.のsolve関数を使う場合が最も遅く、2.と3.ではnを増やすと2.が3.の約2倍で推移します。
def LU_time(preproc, proc):
'''連立方程式を解く時間比較用関数
グローバルな変数nを参照する
'''
while True:
A = rng.integers(-5, 5, size=n**2).reshape((n, n))
if np.linalg.det(A): break
print("前処理に要する時間:", end="")
global ret_preproc
@mytime()
def _():
global ret_preproc
ret_preproc = preproc(A)
print("連立方程式を解く平均時間:", end="")
@mytimeit()
def _():
x = rng.integers(-5, 5, size=n).reshape((n, 1))
b = A@x
if not np.allclose(x, proc(*ret_preproc, b)): print("failed")
n = 1000
1. scipy.linalg.solve
LU_time(
lambda A: [A],
lambda A, b: lin.solve(A, b)
)
2. scipy.linalg.solve_triangular
LU_time(
lambda A: lin.lu(A),
lambda p, l, u, b: lin.solve_triangular(u, lin.solve_triangular(l, p.T@b, lower=True, overwrite_b=True), overwrite_b=True)
)
3. scipy.linalg.lu_solve
LU_time(
lambda A: [lin.lu_factor(A)],
lambda lu_piv, b: lin.lu_solve(lu_piv, b)
)
アルゴリズム
LU分解を用いた連立方程式の解き方が確認できたところで、LU分解の導出方法にフォーカスしてみましょう。
大別すると以下の2つの方法があります。
- ガウスの消去法を利用する方法
- LU分解されたと仮定して計算する方法
ガウスの消去法を利用する方法
ガウスの消去法の前進消去の過程がそのままLU分解になります。
以下の行列$\A$で考えてみます。
n = 3
A, *_ = getAxb(n, by=sp, pivot=True)
A
初期値が単位行列の$\L$と、初期値が行列$\A$と同じ行列$\U$を用意します。
当然ながら$\A = \L\U$となります。
L = sp.eye(3)
U = A.copy()
eq = sp.Eq(A, sp.MatMul(L, U))
print("A = LU:", eq.doit())
eq
前進消去と同様に1行目を定数倍して2,3行目に加えます。
このときの$定数 \times -1$を$\L$の$(2, 1)$, $(3, 1)$に加えます。
E1 = sp.eye(n)
E1[1, 0] = -U[1, 0]/U[0, 0]
E1[2, 0] = -U[2, 0]/U[0, 0]
U1 = E1*U
L1 = E1.lower_triangular(-1)*-1+L
eq = sp.Eq(A, sp.MatMul(L1, U1))
print("A = LU:", eq.doit())
eq
2行目でも同様の操作を行うと$\A = \L\U$となる$\L$と$\U$を得ます。
E2 = sp.eye(n)
E2[2, 1] = -U1[2, 1]/U1[1, 1]
U2 = E2*U1
L2 = E2.lower_triangular(-1)*-1+L1
eq = sp.Eq(L2*U2, sp.MatMul(L2, U2))
print("A = LU:", eq.doit())
eq
前進消去の各段階において$\A$に掛ける基本行列とLU分解の関係は、$\E_2\E_1\A = \U$
すなわち、
$\A = (\E_2\E_1)^{-1}\U$
$\L = (\E_2\E_1)^{-1}$
となります。
sp.Eq(L2, (E2*E1).inv())
実装
上で作成したGauss1をベースに実装したのが下記のLU1関数です。
def LU1(A: np.ndarray):
n = A.shape[0]
m = A.astype(np.float64)
for c in range(n-1):
for r in range(c+1, n):
m[r, c] = ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
return m
Gauss1とLU1の差分
# 縮小表示
t1 = '''
def Gauss1(A: np.ndarray, x: np.ndarray):
n = A.shape[0]
m = np.hstack([A, x]).astype(np.float64)
# 前進消去
for c in range(n-1):
for r in range(c+1, n):
ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
# 後退代入
for r in range(n-1, -1, -1):
m[r, n] /= m[r, r]
m[:r, n] -= m[r, n]*m[:r, r]
return m[:, n:]
'''.splitlines()
t2 = '''
def LU1(A: np.ndarray):
n = A.shape[0]
m = A.astype(np.float64)
for c in range(n-1):
for r in range(c+1, n):
m[r, c] = ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
return m
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
動作確認
A, *_= getAxb(5, by=np, pivot=True)
# lu_factorの結果と比較
np.allclose(lin.lu_factor(A)[0], LU1(A))
計算量
実装を基にした乗除算の計算量は以下の通りで、定数項が無い分ガウスの消去法の前進消去より若干少なめです。
- n-1回繰り返し:$\sum^{n-2}_{c=0}$
c, n = sp.symbols('c n')
sp.Sum((n-c-1)*(n-c), (c, 0, n-2)).doit().simplify()
LU分解されたと仮定して計算する方法
LU分解がなされたと仮定した上で、$\L$, $\U$の各要素に関する式を順次解いていく方法です。
具体的に5×5行列を以下のようにLU分解できたと仮定しましょう。
n = 5
L = sp.Matrix(n, n, sp.symbols(f'l1:{n+1}(1:{n+1})')).lower_triangular(-1)+sp.eye(n)
U = sp.Matrix(n, n, sp.symbols(f'u1:{n+1}(1:{n+1})')).upper_triangular()
A = sp.Matrix(n, n, sp.symbols(f'a1:{n+1}(1:{n+1})'))
sp.Eq(A, sp.Eq(sp.MatMul(L, U), L*U), evaluate=False)
例えば$u_{34}$を求めるには下図の青枠で囲った要素の値を参照する必要があります。

同様に$l_{43}$を求めるには下図のようになります。
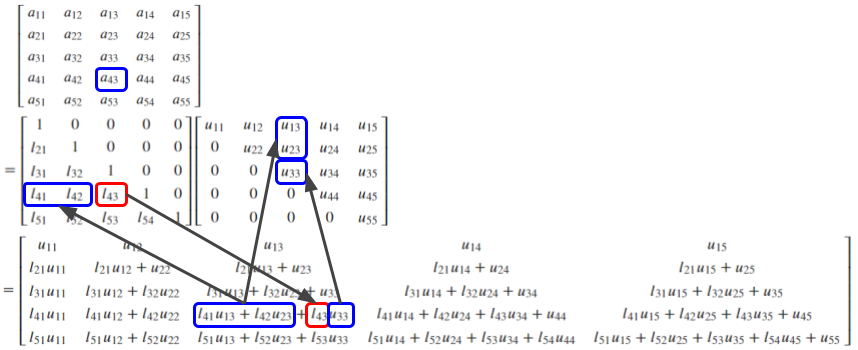
$\U$の1行目、$\L$の1列目は容易に判明するので、値を確定させながら順次内側に向かって計算していくという考え方です。
実装
さて、実装の方向性について、scipy.linalg.lu_factorの戻り値のように$\L$と$\U$を重ねた以下のような行列でを考えてみます。
sp.Matrix(n, n, sp.symbols(f'l1:{n+1}(1:{n+1})')).lower_triangular(-1)+ \
sp.Matrix(n, n, sp.symbols(f'u1:{n+1}(1:{n+1})')).upper_triangular()
計算の順序としては以下の2通りが考えられます。(🟥の要素を求めるために🟦の要素を参照する)
- 下図左:Uの1行目→Lの1列目→Uの2行目→Lの2列目→…のようにUの行(①)→Lの列(②)の順に求める
- 下図右: Uの1行目→Lの2行目→Uの2行目→…のようにLの行(①)→Uの行(②)の順に求める
1. Uの行→Lの列の順に求める

2. Lの行→Uの行の順に求める

これらはメモリアクセスや並列化による効率化を検討する際には重要な要素の一つになるかもしれませんが、少なくとも生のパイソンで試しにLU分解を実装してみたというレベルではどちらでも処理速度に変化はありません。(後述の時間比較を参照)
# 1. Uの行→Lの列の順に求める
def LU2_1(m:np.ndarray) -> np.ndarray:
m = m.astype(np.float64)
n = m.shape[0]
for d in range(n):
# U
for c in range(d, n):
m[d, c] -= m[d, :d]@m[:d, c]
# L
for r in range(d+1, n):
m[r, d] = (m[r, d] - m[r, :d]@m[:d, d]) / m[d, d]
return m
# 2. Lの行→Uの行の順に求める
def LU2_2(m:np.ndarray) -> np.ndarray:
m = m.astype(np.float64)
n = m.shape[0]
for r in range(n):
for c in range(n):
if r > c: # L
m[r, c] = (m[r, c] - m[r, :c]@m[:c, c]) / m[c, c]
else: # U
m[r, c] -= m[r, :r]@m[:r, c]
return m
LU2_1とLU2_2の差分
# 縮小表示
t1 = '''
# 1. Uの行→Lの列の順に求める
def LU2_1(m:np.ndarray) -> np.ndarray:
m = m.astype(np.float64)
n = m.shape[0]
for d in range(n):
# U
for c in range(d, n):
m[d, c] -= m[d, :d]@m[:d, c]
# L
for r in range(d+1, n):
m[r, d] = (m[r, d] - m[r, :d]@m[:d, d]) / m[d, d]
return m
'''.splitlines()
t2 = '''
def LU2_2(m:np.ndarray) -> np.ndarray:
m = m.astype(np.float64)
n = m.shape[0]
for r in range(n):
for c in range(n):
if r > c: # L
m[r, c] = (m[r, c] - m[r, :c]@m[:c, c]) / m[c, c]
else: # U
m[r, c] -= m[r, :r]@m[:r, c]
return m
'''.splitlines()
diff.HtmlDiff().make_file(t1, t2)
動作確認
A, *_= getAxb(5, by=np, pivot=True)
# lu_factorの結果と比較
# 1. LU2_1
print("myLU2_1: ", np.allclose(lin.lu_factor(A)[0], LU2_1(A)))
# 2. LU2_2
print("myLU2_2: ", np.allclose(lin.lu_factor(A)[0], LU2_2(A)))
計算量
LU2_1関数で乗除算の計算量を数えると以下のようになりますが、結果としてガウスの消去法を用いる方法と同じです。
- n回繰り返し:$\sum^{n-1}_{d=0}$
d, n = sp.symbols('d n')
sp.Sum((n-d)*d + (n-d-1)*(d+1), (d, 0, n-1)).doit().simplify()
時間比較
例によって時間比較ですが、ほとんど差はなく、scipyによるLU分解(上の時間比較での「前処理に要する時間」)と比べると圧倒的に遅いです。
n = 100
A, *_ = getAxb(n, by=np, pivot=True)
mytime()(lambda: LU1(A));
mytime()(lambda: LU2_1(A));
mytime()(lambda: LU2_2(A));
LDU分解とCrout, Doolittle形式
以下のような下三角行列$\L$と対角行列(diagonal matrix)$\D$、上三角行列$\U$によって$\A = \L\D\U$となるように分解することをLDU分解といいます。
$\L = \expLunit, \D = \expD, \U = \expUunit$
実装は簡単で、上で定義したLU1関数に1行加えるだけです。
def LDU(A: np.ndarray):
n = A.shape[0]
m = A.astype(np.float64)
for c in range(n-1):
for r in range(c+1, n):
m[r, c] = ratio = m[r, c]/m[c, c]
m[r, c+1:] -= ratio*m[c, c+1:]
m[c, c+1:] /= m[c, c] # 追加
return m
動作確認
A, *_= getAxb(5, by=np, pivot=True)
ldu = LDU(A)
# LDUそれぞれで2次元のndarrayにする
l = np.tril(ldu, -1) + np.eye(5)
d = np.diag(np.diag(ldu))
u = np.triu(ldu, 1) + np.eye(5)
# A = LDU
np.allclose(A, l@d@u)
ところで、これまで見てきたLU分解はすべて$\L$の対角成分が1となっていました。
すなわち、$\A = \L\U = \L'\D'\U'$とすると、$\U = \D'\U'$として扱っていたことになります。
それに対して$\L= \L'\D'$として$\U$の対角成分を1にするような形も考えられます。
前者をDoolittle's method、後者をCrout's methodと呼ぶようです。
"method"と言うからにはアルゴリズム的な違いがありそうなものですが、実際には上で紹介した方法を微修正すればよいので、"method"というより"形式"ぐらいのほうが個人的にはしっくりきます。
既存のライブラリで手っ取り早くCrout形式のLU分解を得るには、例えば以下のような方法があります(列でのピボット選択になってしまうが…)。
n = 3
A, *_= getAxb(n, by=np, low=-10, high=10)
_p, _l, _u = lin.lu(A.T)
p = _p.T
l = _u.T
u = _l.T
print("A = LUP:", np.allclose(A, l@u@p))
# 見やすくするためsympyに変換
sA, P, L, U = map(n2s, [A, p.astype(int), l, u])
sp.Eq(sp.MatMul(sA), sp.MatMul(L, U, P))
参考資料
